The BrainSTEM import tool helps you add data to BrainSTEM by uploading CSV files. Instead of creating CSV files from scratch, you download pre-built templates for each data type, edit them with your data, and upload them.
How it works: Download template → Edit with your data → Upload → Review results
Interface Overview
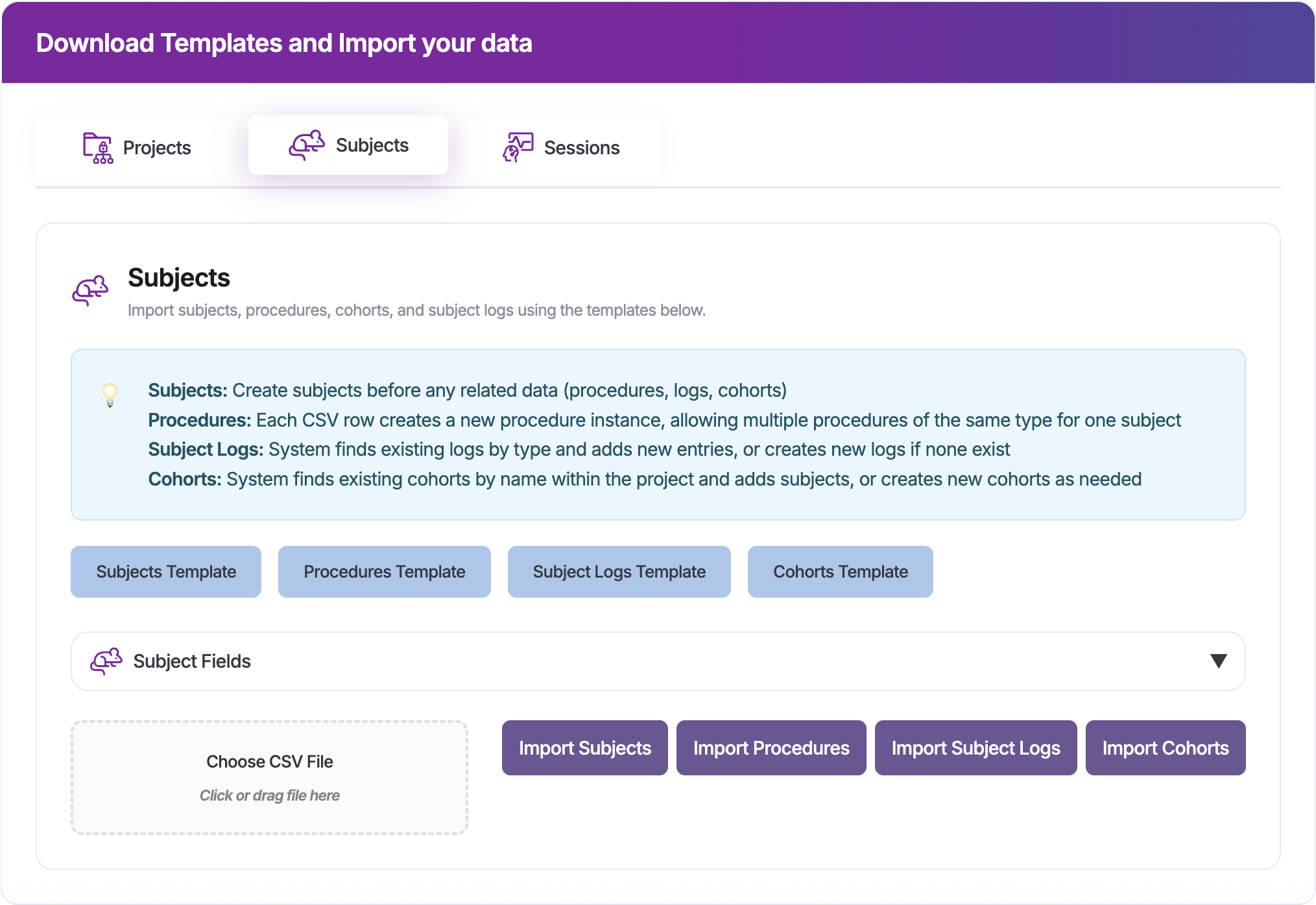
The import tool interface is organized into three main tabs: Projects, Subjects, and Sessions. Each tab provides templates and import functionality for related data types.
Main Navigation Tabs
Projects - Import projects and project-related data
Subjects - Import subjects, procedures, cohorts, and subject logs
Sessions - Import sessions, behaviors, data acquisition, manipulations, epochs, and collections
Template Downloads
Each tab displays relevant template download buttons:
Blue template buttons - Download pre-configured CSV templates for each data type
Templates include example data and proper column formatting
Multiple templates available per tab (e.g., Subjects tab has Subjects, Procedures, Subject Logs, and Cohorts templates; Sessions tab has Sessions, Behaviors, Data Acquisition, Manipulations, Epochs, and Collections templates)
Import Process
Choose CSV File - Drag and drop or click to select your completed CSV file
Select Import Type - Click the appropriate purple import button for your data type
Review Results - Check the import results for any errors or warnings
Select your data type (e.g., “subjects”, “procedures”)
Click “Download CSV Template”
Open the downloaded file and replace the example data with your data
Upload the modified CSV file
Check the results for any errors
Why Use Templates?
No mistakes - Templates have correct column names and formatting
Faster - All required fields are already included
Better examples - Shows you exactly how to format your data
Finding Your UUIDs
Templates use YOUR_*_ID placeholders for existing BrainSTEM data. To find these IDs:
Navigate to the relevant admin section (Procedures, Equipment, etc.)
Click edit/view on your record
Copy the UUID from the URL (long string of letters and numbers)
Input conventions
Column headers must follow the pattern <entity>__<field> and match exactly; unrecognised columns are ignored.
CSVs are parsed with Python’s built-in csv module (via our lightweight helpers), so values may be wrapped in double quotes or left bare—both are accepted.
Trimming happens automatically, but lookups remain case-sensitive. Keep names ≤200 characters to stay within model limits.
Boolean fields treat true, yes, 1, on, and enabled (any casing) as True; anything else—including blanks—evaluates to False.
Datetimes accept ISO strings that include seconds (e.g. 2024-05-01T14:30:00 or 2024-05-01T14:30:00Z) alongside spaced formats (2024-05-01 14:30, 2024-05-01 14:30:45) and their month/day variants.
Date-only fields must use ISO YYYY-MM-DD (optionally with a time component that is ignored).
Fields that expect multiple values (for example cohort__subjects, collection__sessions) take comma-separated lists; tags are passed through exactly as provided, so keep any desired commas in the single string.
JSON columns must contain valid JSON objects; malformed JSON raises a warning and the field is skipped. Example: {"laserPower": 5, "units": "mW"}.
Rich-text fields (project, subject, session, cohort, collection descriptions) are backed by CKEditor and therefore accept HTML. Because inline scripts and event handlers will render, keep inputs to simple formatting (paragraphs, bold, italics, links) to avoid introducing interactive content.
Data Type Details
Projects
Field
Accepted Input
Notes
project__name*
Text (e.g. Auditory Cortex Project)
Must be unique across BrainSTEM; importer creates the project when it does not exist.
project__description
Plain text or limited HTML (e.g. <p>Two-photon recordings.</p>)
Stored in the rich-text description field; avoid interactive markup.
project__is_public
Boolean keywords (e.g. true, no, 0)
Parsed via parse_boolean; blank values become false.
project__tags
Comma-separated tags (e.g. vision, cortex)
Converted into individual tag names.
project__authenticated_groups
Comma-separated group names (e.g. "Petersen Lab - UCPH,Neurology Team")
Groups start with contributor (can_change: true) access. Use quotes for multiple groups.
Each UUID is validated individually; invalid IDs raise warnings.
procedure__details
JSON object (e.g. {"virus": "AAV9"})
Parsed into type_json; schema defaults are loaded if omitted.
Subject Logs
Field
Accepted Input
Notes
subject__name*
Existing subject name (e.g. Mouse_001)
Subjects must exist before logging entries.
subject_log__type*
Subject-log type code (e.g. TrainingSession)
Example values: Housing, WaterDeprivation, Handling.
subject_log__description
Plain text (e.g. Habituation to head-fix.)
Stored on the log record (500 characters).
subject_log__entry_datetime
Datetime (e.g. 2024-05-02 10:00)
Required for single-point logs (anything not in the start/end list below).
subject_log__entry_start_datetime
Datetime (e.g. 2024-05-02 10:00)
Required for Housing, FoodDeprivation, WaterDeprivation, Habituation, Handling, TrainingSession.
subject_log__entry_end_datetime
Datetime (e.g. 2024-05-02 11:00)
Optional for the start/end list; defaults to one hour after the start when omitted.
subject_log__entry_notes
Plain text (e.g. Handled by J.D.)
Saved with the log entry.
subject_log__entry_data
JSON object (e.g. {"task": "Go/No-Go"})
Parsed into the entry details field.
The importer finds or creates a SubjectLog for the subject/type pair, then adds a log entry when any entry timestamps are present. Duplicate entries for the same timestamp receive warnings and are counted as existing records.
Sessions
Field
Accepted Input
Notes
project__name*
Existing project name (e.g. Auditory Cortex Project)
Projects must exist before importing sessions.
session__name*
Text (e.g. Session_001)
Session names are globally unique.
session__description
Plain text or limited HTML (e.g. <p>Baseline recording.</p>)
Stored in the session’s rich-text description; avoid interactive markup.
session__date_time
Datetime (e.g. 2024-05-10T13:45:00)
Parsed and stored as ISO-8601.
session__tags
Comma-separated tags (e.g. baseline, imaging)
Converted into individual tag names.
session__data_storage
Data storage UUID (e.g. a1b2c3d4-...)
Must reference an existing data storage record; warnings are emitted when not found.
session_name_in_data_storage
Text (e.g. 2024-05-10_baseline)
Optional alias for storage systems.
Behaviors
Field
Accepted Input
Notes
session__name*
Existing session name (e.g. Session_001)
Sessions must exist before importing behaviors.
subject__name*
Existing subject name (e.g. Mouse_001)
Subjects must exist before importing behaviors.
behavior__setup*
Setup UUID (e.g. d3d0...)
Validated via the Setup endpoint.
behavior__behavioral_paradigm*
Behavioral Assay UUID (e.g. f6d4...)
Validated via the Behavioral Assay endpoint.
Data Acquisition
Field
Accepted Input
Notes
session__name*
Existing session name (e.g. Session_001)
Sessions must exist before importing data acquisition records.